
Teaching a robot to understand language is no small feat. At first, it’s great at handling simple tasks like recognizing words or answering straightforward questions. But what happens when you throw something more complex at it, like a novel or a detailed research paper? This is where BERT and SMITH Algorithm come in. BERT was the breakthrough model that revolutionized how machines process language. However, as the need for handling more complex and longer texts grew, SMITH emerged as the solution to the challenges BERT couldn’t quite handle.
So, how do these models tackle everything from quick tweets to lengthy documents with precision? Let’s explore how BERT and SMITH work, what makes them stand out, and how they’re shaping the future of natural language processing (NLP).
What is BERT?
BERT, which stands for Bidirectional Encoder Representations from Transformers, is a machine learning model developed by Google that has significantly advanced the field of natural language processing (NLP). Unlike traditional models, BERT takes a bidirectional approach, analyzing text by looking at the context of words from both directions at once. This allows it to understand language on a much deeper level.
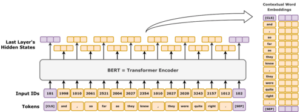
BERT’s ability to grasp the language has made it invaluable for tasks like answering questions, completing sentences, and analyzing text. By considering the meaning of words within their broader context, it provides a more accurate and sophisticated understanding of language, setting a new standard for NLP models.
How Does BERT Work?
BERT is built on a machine learning architecture called Transformers, which is a game-changer in NLP. Unlike traditional models that process text sequentially (one word at a time), Transformers allow BERT to process the entire input text at once. This means BERT can grasp the relationships between all the words in a sentence, whether they come before or after a given word.
To understand this, take the sentence:
“He went to the bank.”
Without additional information, it’s ambiguous—does “bank” refer to a financial institution or the side of a river? BERT disambiguates this by analyzing the surrounding words. If the sentence continues with “to withdraw cash,” BERT understands that “bank” refers to a financial institution. If the next words are “to go fishing,” BERT infers a riverbank. This contextual awareness is what sets BERT apart from older models.
BERT undergoes two key phases:
- Pre-training: It learns general language understanding by predicting missing words in sentences and determining if two sentences logically follow each other.
- Fine-tuning: After pre-training, BERT is customized for specific tasks (e.g., answering questions, classifying emails) by training it further on smaller, task-specific datasets.
Where Does BERT Algorithm Shine?
BERT’s ability to understand context with exceptional precision has made it a game-changer across industries, transforming how organisations process and interpret language.
In search engines, for instance, Google’s integration of BERT revolutionised how queries are understood. Complex or conversational questions, such as “Can you get medicine for someone pharmacy?” are no longer misinterpreted, as BERT deciphers intent even when the phrasing is unclear. Similarly, chatbots and virtual assistants like Alexa and Google Assistant have become more intuitive, offering responses that feel human-like by grasping the deeper meaning behind user queries.
Marketing teams leverage BERT for sentiment analysis, distinguishing between glowing praise (“This product is amazing!”) and harsh criticism (“This product is a complete disaster”). Its knack for understanding emotions in text enables businesses to adapt and respond effectively to customer feedback. In machine translation and text summarization, BERT shines by generating accurate translations and condensing lengthy documents into digestible summaries without losing key details.
Even highly specialized fields benefit from BERT’s capabilities. In healthcare, it analyzes medical records and research, while in law, it helps parse contracts and extract critical information from case files. Whether it’s simplifying complex tasks or making interactions more natural, BERT has redefined what’s possible with language-based AI.

The Downside of BERT
While BERT has revolutionized natural language processing, it is not without its challenges. One significant limitation is its difficulty handling long texts, as it processes inputs in fixed chunks of up to 512 tokens, often leading to a loss of context when working with lengthy documents.
Additionally, BERT’s impressive capabilities come at a high computational cost, requiring advanced hardware and substantial memory, which can be a barrier for smaller organizations or individual developers. Its performance is also heavily dependent on the quality and diversity of the data it is fine-tuned on; biased or poorly curated datasets can result in skewed outputs or inaccuracies. Furthermore, while BERT excels in understanding language, it struggles with tasks requiring complex logical or mathematical reasoning, often necessitating the use of supplementary models. These limitations highlight the need for careful consideration and adaptation when deploying BERT in practical applications.
What is SMITH?
SMITH, short for Segmented Multi-instance Transformer Hierarchies, is a cutting-edge natural language processing (NLP) model designed to tackle a significant challenge: understanding long-form text. While models like BERT excel at short passages, their performance diminishes with lengthier documents. SMITH bridges this gap by handling extended content with remarkable accuracy. It was developed to process long text inputs, such as research papers, books, or lengthy legal documents, where traditional models fall short.
Imagine SMITH as the heavyweight champion of long-text comprehension, adept at breaking down and analyzing complex narratives, extracting insights, and summarizing large-scale information.
How Does SMITH Algorithm Work?
SMITH processes lengthy documents by breaking them into smaller, coherent segments and analyzing them hierarchically. Each section, such as a paragraph or a chapter, is individually examined to extract insights. These insights are then combined to create a comprehensive understanding of the entire document, much like assembling a puzzle where each piece contributes to the overall picture. Its hierarchical transformer-based architecture goes beyond analyzing sections in isolation, identifying relationships and themes that connect across the text. This method enables SMITH to handle complex, long-form content with exceptional clarity and depth.
Where Does SMITH Shine?
While BERT processes text in fixed-sized chunks (up to 512 tokens), SMITH overcomes this limitation by using a hierarchical structure. Instead of losing context when processing long texts, SMITH maintains a high level of coherence across all segments. Its ability to connect themes and ideas makes it better suited for long-form text, where context often spans multiple sections.
BERT vs SMITH: Key Differences
| BERT | SMITH |
|---|---|
| Designed to understand words within the context of sentences | Capable of understanding entire documents and long-form content |
| Analyzes the full context of a word by looking at words before and after it | Comprehends blocks of sentences within the context of the whole document |
| Limited to processing short documents or paragraphs | Better suited for analyzing longer documents |
When it comes to BERT and SMITH, the main difference lies in what they’re built for. BERT (Bidirectional Encoder Representations from Transformers) is like the go-to tool for quick, precise tasks—think of it as a sprinter. It’s designed to handle shorter pieces of text, like sentences or short paragraphs, by analysing words in all directions at once to understand context. This makes it super fast and efficient for tasks like powering chatbots, analysing sentiments in reviews, or optimising search queries.
SMITH (Siamese Multi-depth Transformer-based Hierarchical Model), on the other hand, is built for the long haul. It’s like a marathon runner, engineered to process lengthy documents by breaking them into chunks, analysing each piece separately, and then piecing everything together for a complete understanding. This makes SMITH perfect for summarizing detailed reports or comparing articles for similarities. However, all that heavy lifting comes with a cost—SMITH needs more computational resources and time compared to BERT’s streamlined, faster design. In short, BERT is best for quick, focused tasks, while SMITH shines when depth and endurance are needed.
When to Use BERT or SMITH

How do you decide which model to use? It depends on your task:
Choose BERT for Everyday Tasks:
- Powering chatbots that respond instantly.
- Analysing social media to gauge public sentiment.
- Answering FAQ-style queries quickly and accurately.
Choose SMITH for Complex, Long-Form Tasks:
- Summarizing detailed reports for busy executives.
- Finding patterns across long legal documents.
- Analyzing academic research papers to extract key insights.
Analogy: “BERT is like a sprinter—quick and agile for short distances. SMITH, on the other hand, is a marathon runner—steady and powerful over long distances.”
Challenges with Both Models
Running models like BERT and SMITH efficiently comes with its challenges, particularly in terms of computational costs. Both models require powerful hardware to function optimally, but SMITH takes it a step further. Its hierarchical architecture—designed to handle long and complex texts—demands significantly more resources than the simpler, more streamlined BERT. This means higher expenses for processing power, memory, and infrastructure. For small businesses or independent researchers who may not have access to cutting-edge GPUs or cloud resources, this cost can be a substantial barrier to adoption, making it challenging to fully utilise these models.
Training these models is another hurdle, especially for SMITH, which involves a far more intricate process. While BERT focuses on shorter texts and processes data relatively quickly, SMITH’s ability to break down and analyse long documents adds extra layers to its training process. Each of these layers takes additional time and computational effort to fine-tune, significantly slowing down the training pipeline. For projects with tight deadlines or limited budgets, this extended training time can make SMITH impractical compared to BERT, which is faster to set up and deploy.
Conclusion
Both BERT and SMITH come first as AI models. BERT is your best friend for quick, sentence-level tasks, while SMITH is the go-to for tackling complex, long-form texts.
As these models continue to evolve, their potential applications are endless. Whether you’re building a chatbot or analysing a stack of research papers, BERT and SMITH offer powerful solutions. The best part? Both models are open-source, so you can experiment with them yourself.



